Data Pipeline Design Patterns That Stand the Test of Time
Technology changes.
Vendors change.
Tools evolve.
Buzzwords rotate every 18 months.
But strong data pipeline design?
That should outlive platforms, trends, and hype cycles.
Whether you’re building in a modern lakehouse, a cloud warehouse, or consolidating ten legacy systems into one environment, certain data pipeline patterns consistently prove durable.
These are the patterns that don’t just “work today.”
They scale. They adapt. They survive.
Let’s walk through the ones that truly stand the test of time.
1. The Layered (Medallion) Architecture
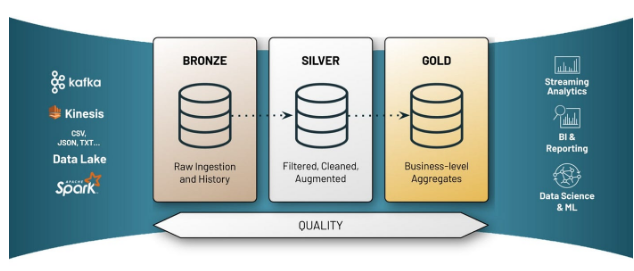
If there’s one pattern that consistently holds up, it’s the layered model — often called Bronze, Silver, Gold.
Bronze (Raw Layer)
Direct ingestion from source systems
Minimal transformation
Full fidelity of source data
Append-only when possible
Silver (Refined Layer)
Cleaned, standardized
Deduplicated
Conformed dimensions
Basic data quality applied
Gold (Business Layer)
KPI logic
Aggregations
Reporting-ready tables
Domain-specific views
Why does it last:
Raw data is preserved.
Business logic is isolated.
Definitions can evolve without breaking ingestion.
Auditability is built in.
When KPIs change — and they always do — you adjust the Gold layer. You don’t rebuild the world. This pattern scales across industries, tools, and architectures.
2. Idempotent Processing
This one isn’t flashy. It’s foundational. An idempotent pipeline means that running it twice produces the same result.
Why this matters:
Pipelines fail.
Jobs retry.
Network interruptions happen.
Schedules overlap.
If your system double-counts revenue because a job re-ran, you don’t have a pipeline — you have a liability.
Design patterns that enable idempotency:
MERGE (upsert) instead of INSERT
Natural or surrogate keys
Change Data Capture (CDC)
Watermarking for incremental loads
Deterministic transformations
This is one of those patterns that separates hobby projects from enterprise systems.
3. Incremental Processing Over Full Reloads
Early-stage systems often rely on full refreshes. They’re easy to build, and they don’t scale. A durable pipeline minimizes compute by processing only what changed.
Patterns that support this:
Timestamp-based incremental loads
CDC (Change Data Capture)
Event-based streaming
Partition-based processing
Incremental pipelines:
Reduce cost
Reduce runtime
Enable near real-time updates
Scale with data growth
Full refreshes feel simple while incremental design feels mature.
4. Schema Evolution Handling
Data sources change. Often without notice, new columns appear, fields get renamed, and types change. A pipeline that breaks every time a source system updates is fragile.
Design patterns that endure:
Schema-on-read flexibility in raw layers
Automatic schema inference with guardrails
Versioned transformations
Contract-based ingestion
The Bronze layer should absorb schema volatility, while the Silver and Gold layers should stabilize it. That separation makes your architecture resilient.
5. Data Contracts Between Teams
As organizations grow, pipelines break not because of tech, but because of misalignment.
Finance changes the definition.
Operations modify a process.
Engineering renames a field.
A durable pattern is explicit data contracts:
Defined schemas
Defined SLAs
Defined field meanings
Defined ownership
This isn’t just documentation; it’s governance baked into design. Pipelines last longer when accountability is clear.
6. Observability and Monitoring Built In
If you find out something is broken because a dashboard looks wrong, you’re already too late.
Modern durable pipelines include:
Row count checks
Null threshold checks
Freshness validation
Volume anomaly detection
SLA tracking
I cannot be just logs. It needs to be actual alerting. Data observability is not optional anymore; it’s infrastructure. The pattern that stands the test of time is this: Every pipeline should be self-aware.
7. Separation of Ingestion and Business Logic
One of the most common architectural mistakes is hardcoding business logic into ingestion pipelines.
For example:
Calculating KPIs during ingestion
Embedding business rules in raw loads
Applying aggregations before storing raw data
This creates tight coupling.
A better pattern:
Ingestion handles data movement.
Transformation handles standardization.
Modeling handles business logic.
When these are separated:
Teams can move independently.
Definitions can change safely.
Systems scale cleanly.
Coupling kills longevity. while modularity sustains it.
8. Event-Driven Architecture (When Appropriate)
Batch pipelines still matter, but event-driven systems are increasingly foundational.
Patterns include:
Streaming ingestion
Message queues
Event logs
Micro-batch processing
Why does it last:
Enables real-time analytics
Supports reactive systems
Reduces latency between action and insight
You don’t need streaming everywhere. But designing pipelines that can support it while future-proofing your architecture
9. Reusable Transformation Frameworks
Pipelines that last avoid one-off scripts. Instead, they build reusable components:
Standard merge templates
Shared data quality modules
Common dimension frameworks
Parameterized jobs
Centralized orchestration patterns
Why this matters:
New pipelines get built faster.
Errors are reduced.
Governance is consistent.
Teams scale more easily.
Reusability is quiet power.
10. Lineage and Traceability
When a metric is questioned, can you answer:
Where did this number come from?
Which source system?
Which transformation?
Which version of logic?
Durable pipelines include:
Metadata tracking
Table-level lineage
Column-level lineage (when possible)
Version-controlled transformations
Trust in data doesn’t come from dashboards. It comes from traceability.
11. Security by Design
Security should not be layered on later.
Long-lasting patterns include:
Role-based access control
Layer-based permissioning
PII masking at Silver/Gold layers
Environment separation (dev/test/prod)
As organizations mature, compliance expectations increase. Pipelines built with security as an afterthought often require painful retrofits. Designing secure foundations early is cheaper in the long term.
12. Decoupled Orchestration
Hard-coded dependencies are brittle. A better pattern:
Central orchestration
Explicit dependency graphs
Retry logic
Failure isolation
If one downstream transformation fails, ingestion shouldn’t stop. Resilience is a design decision.
13. Domain-Oriented Data Ownership
As organizations scale, central data teams become bottlenecks. An increasingly durable pattern:
Domain-based modeling.
Finance owns financial logic.
Operations owns operational metrics.
Marketing owns campaign definitions.
The platform team enables infrastructure. Domains own meaning. This scales far better than centralizing every decision.
14. Version-Controlled Transformations
Pipelines built in notebooks without version control degrade over time.
Durable pipelines:
Store transformations in Git
Use CI/CD pipelines
Promote through environments
Track changes over time
This enables:
Auditability
Safe rollbacks
Peer review
Controlled releases
Engineering discipline extends pipeline life.
15. Design for Change, Not Perfection
The most durable pattern of all:
Assume change.
KPIs will evolve.
Systems will consolidate.
Vendors will be replaced.
Leadership will shift priorities.
AI initiatives will demand raw data access.
If your pipeline assumes stability, it won’t last. If your pipeline assumes volatility, it will thrive.
What Actually Makes a Pipeline “Timeless”?
It’s not the tool. It’s not the platform. It’s not whether you use SQL, Python, or Spark.
It’s whether the design:
Preserves raw data
Separates concerns
Handles change gracefully
Scales incrementally
Enforces governance
Builds observability in
Enables traceability
Technology evolves. Strong architecture principles do not.
Final Thought
The data world loves trends. First, it was data warehouses. Then data lakes. Then lakehouses. Then streaming everything. Then AI-first architectures.
But the pipelines that survive across all of these eras follow the same enduring patterns:
Layered design.
Idempotency.
Incrementality.
Modularity.
Observability.
Governance.
The real goal of pipeline design isn’t just to move data. It’s to create a system that the business can trust — today and five years from now. Because the best data pipeline is not the one that works right now, it’s the one that keeps working as everything else changes.